I spoke to Google about their AI that can play at StarCraft 2 Grandmaster level
Impressive, but worth scrutinising


I wonder what the last "AI does a thing" headline will ever be. The one Google DeepMind are imagining, on their quest to create a genuine general intelligence, is something like "AI can do everything far better than you, nuh nuh". By their measure, their AI AlphaStar has climbed one more rung towards that goal by reaching Grandmaster level on StarCraft 2's European servers. That means it can't beat the very best, but it is "within the top 0.15% of the region's 90,000 players".
That's impressive, especially considering the greater limits on its perspective and actions per minute since the last time DeepMind sent it to do battle. This version can play all three races on any map, and is limited to a camera perspective in a similar way to a human player. It's a neat accomplishment, but I'm glad I got the chance to talk to the team and poke a caveat or two out of them.
Back in July, European players saw a checkbox that let them opt-in to potentially facing Google's bot. Google have now published their bots accomplishments in Nature. The actual study is behind a paywall, but Nature also published an article with most of the key details.
They trained their AI by getting it to watch real players, then by pitting it against "exploiters". These were agents deliberately designed to poke holes in AlphaStar's strategies. Pro player Dario "TLO" Wünsch has been involved with the project since before a previous, less limited version of AlphaStar trounced him back in January.
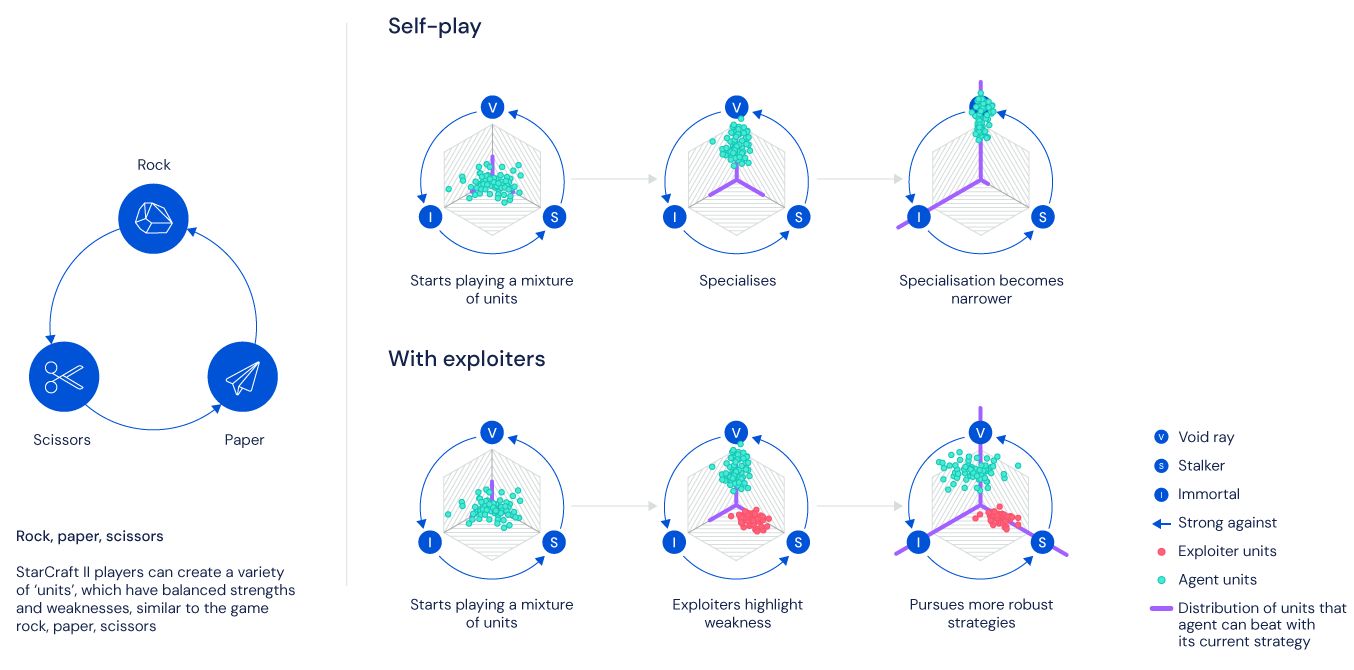
He showed me a sample match where AlphaStar plugged a planned gap in a defensive wall of buildings with a single unit. I asked if that behaviour could be attributed to the exploiters, and research scientist Oriol Vinyals jumped in to tell me it was a product of standard reinforcement learning but "especially" the exploiters. If the wall wasn't perfect, an exploiter agent would be likely to sneak through.
Those limitations I mentioned are crucial. Vinyals told me this new version of AlphaStar can never take more than 22 actions within a space of five seconds, and there are longer time windows "just to ensure the average action rate is also reasonable". Importantly, it "never spikes at anything (they) saw as being statistically too high compared to good players". The actual paper states that the peak APM is lower that professional players, although it's worth noting this doesn't pay heed to how humans are more likely to 'waste' actions by spamming the same command.
The other key restriction is that this version of AlphaStar can only "see" the part of the game that it holds its camera over. DeepMind are keen to give the impression it's seeing the same game as the human, but that claim has nuances that need scrutinising. Vinyals was happy to oblige: "What's meant here precisely is that at no point Alphastar is given information that would not in principle be available to a human camera perspective. Alphastar can't do actions outside of its camera view. It probably sees certain things, maybe more preci-"
At that point he stopped, tellingly. "Well maybe more precisely's not the right word, but it's different. The perception is through a computer interface, it sees numbers, turning binary information into data."

Dario more helpfully boiled it down to how in a close situation with, say, 32 units vs 31 units, the AI might be able to figure out it has the advantage - but he stressed these were fringe cases, and that humans are good at intuiting results. He also brought up all the many mistakes he's seen AlphaStar make, like blowing up its own units with an AOE ability. "Some units it controls better, some units it controls worse", he said. "From that perspective it feels very fair". Vinyals estimated its capacity to precisely click on the map, or clicking's analogue, to be "probably about half a mid-sized unit".
Fairness is key, for Google. Vinyals told me he's very interested in getting the AI to make real time decisions, like where it should focus its camera. He wants it to 'think' things like "I couldn't possibly control these units perfectly, so maybe I just move them away and come back to these later". According to him, "The skills AlphaStar developed were made possible because of the limitations we imposed."
Dario backed this up, telling me that "The playstyle before the limitations was a little bit degenerate. Often a single unit would be favoured, and a single attack that's perfectly executed would end the game. Very quickly after the APM restrictions were introduced I saw a more diverse strategy, a deeper exploration of the game. That's a really cool takeaway: once something is less capable mechanically, more intelligence might emerge."

There's another sense in which fairness is important. If AlphaStar's sophistication was the result of DeepMind throwing money and computing power at only minorly improved algorithms, the achievement would be less impressive. Naturally, the team was keen to reassure me this wasn't the case. Researcher David Silver told me they've been working on the project for roughly two years, and compared the project's scope to other Google projects like AlphaGo and AlphaZero.
Vinyals told me they used the same computing resources that many people in academic institutions use to "train image models and so on", and Silver claimed that an academic institution could probably mirror their results "if they used their resources effectively". He told me I could work out the total financial cost from the information in the paper, but that he doesn't think it would come to "a shocking number." Vinyals estimated that they've used this hardware to let AlphaStar play for the equivalent of roughly 200 human years, a figure he compared favourably to the thousands or millions of years that would technically be possible.

Both me and AI wizard Mike Cook, who graciously let me pick his brains for this article, think much of the accomplishment's significance rests on how much can be attributed to money and how much to ingenuity. Silver told me that the question Deep Mind are ultimately pursuing is "can we acquire the level of intelligence and general learning capabilities that humans have", and that they "want to start in the context of games to be able to demonstrate that."
There's the rub. This is an impressive demonstration of how an organisation with large resources can create an AI that beats 99.85% of humans at StarCraft, crucially by playing in a similar way to them. To what extent that constitutes a step towards general intelligence is a question that's beyond the scope of this article. All I'll do for now is ask it.